设计模式:Bridge
针对问题
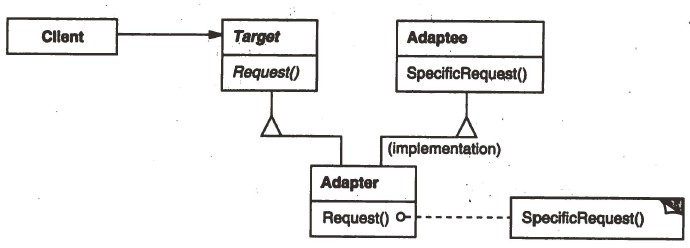
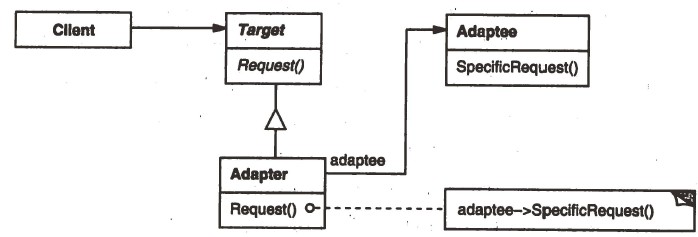
一个函数通常会包括声明与实现两部分。简单的说,声明的是“做什么”,而实现的内容则是“怎么做”。
在使用继承的面向对象设计中,通过对同一基类的继承,可以让基类中的同一个函数声明在不同派生类中有多个不同的实现。但是,在“派生”一个新类后,这个类所构造实例对象的函数声明和实现在编译时将绑定在一起。也就是说,虽然对于同一个接口,我们可以更换不同的对象来更改它的实现,但是对于同一个对象,它的某个函数的实现方式在编译时就已经确定,运行时无法修改。
Bridge模式则是将声明与实现放在两个不同的对象中,对于同一个对象,它某个函数的实现方式不是唯一的。
而另一个关于继承的问题则是派生类的继承层次问题:因为底层实现代码被绑定在派生类中,如果某个接口下有一个树形的继承关系,那么实现代码将出现在每一个叶子派生类中。如果我们要更换底层实现,那么就要为每一个叶子派生类创建一个平级的替换实现类,这个工作量是庞大的。… Read the rest