记一次集群内无可用http服务问题排查
1.摘要
前一阵子发现服务会有偶发的服务不可用的情况,记录一下这个问题的排查过程。
现象是这样的:每天到了某个时间点,就会出现服务不稳定的情况,偶发接口调不通。
线上业务使用了lvs-nginx-tomcat三层结构,首先查看tomcat监控,没有什么特别异常的情况,响应时间和错误码没发现有什么异常,CPU、IO等等指标也都正常。
再查看nginx上的监控,发现在某个时刻这个服务的5xx报错突增,大概7、8秒之后又恢复了。
继续在nginx服务器上找线索,发现Nginx在那个时间点会出现报错:
|
1 2 |
2015/12/24 10:30:38 [error] 13433#0: check time out with peer: 10.79.40.1xx:80 |
线上nginx会每秒探测后端所有服务器的某个uri,如果返回的http状态码是200则认为正常,连续3次探测失败则摘除探测失败的服务器,直到探测成功再恢复。
从日志中可以发现nginx在出问题的时间点对于后端所有tomcat的探测请求都出现了问题,导致摘除了所有后端服务器,在这段时间里请求会报502异常。
从nginx上的日志可以看到探测请求没有返回,那么请求实际发到tomcat了没有?线上业务中的探测频率是1s/次,于是到tomcat的访问日志里查找线索,过滤一个nginx对tomcat的所有探测请求:
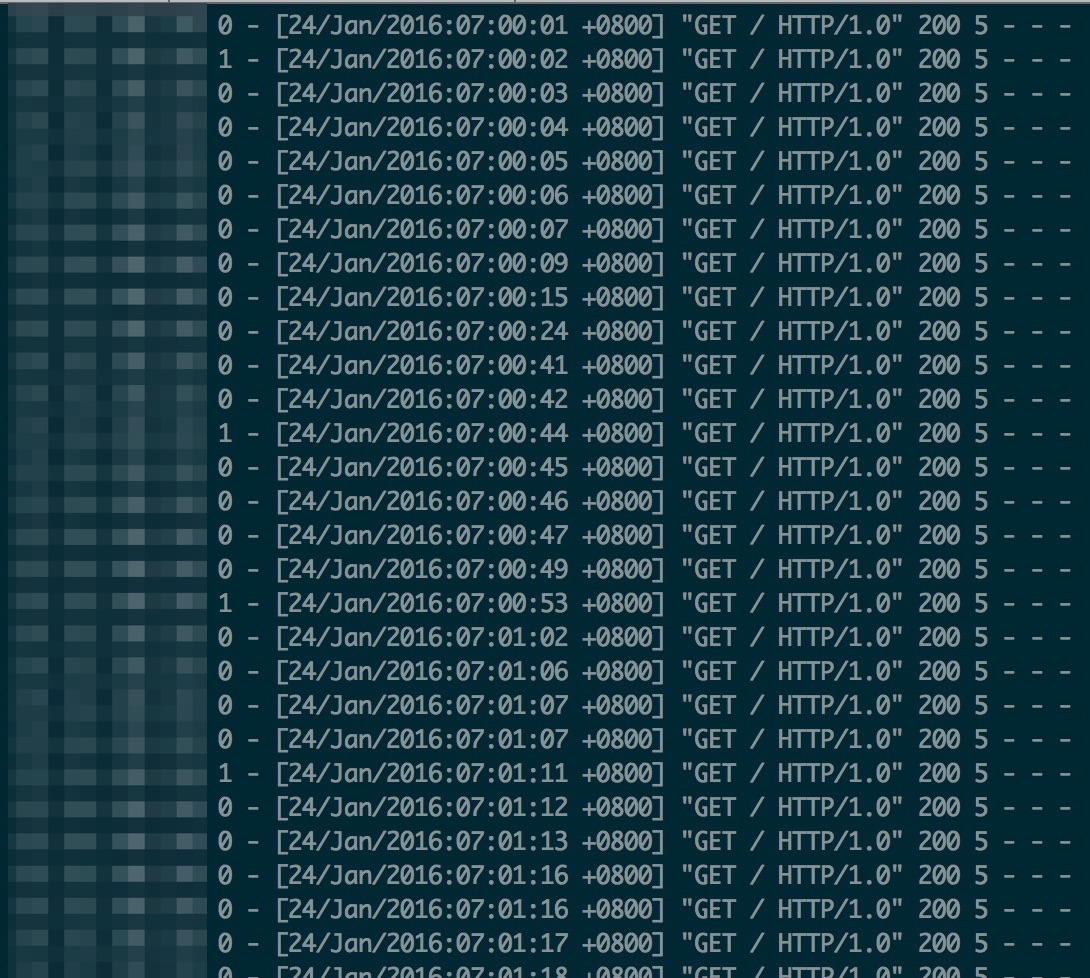
可用看出从7:00:10-7:00:40左右的探测请求是有丢失的。
前端机的负载并不高,于是我们第一时间认为这可能是nginx到tomcat服务器的网络有问题。统计了一下线上日志,出问题的机器集中在某个网段,并且集中在一天之内的某几个时间点,这似乎也进一步印证了我们的猜测。
但到此为止仅仅是怀疑,为了证明我们的猜测,我们尝试去复现问题。我们在nginx上部署了一个简单的脚本,用curl命令对同样的tomcat发起每秒一次的请求,但结果比较诡异:
| 监测方式 | 监测地址 | http版本 | 频率 | 所在服务器 | 目的服务器 | 问题 |
|---|---|---|---|---|---|---|
| nginx | / | 1.0 | 1s | nginx | tomcat | 有 |
| curl | / | 1.0 | 1s | nginx | tomcat | 无 |
这跟我们之前的猜测不一致,没办法,尝试在两端抓包查看网络状况,
tomcat抓包:

nginx抓包:

tomcat服务器在7:00:10已经接收了请求并且回复了ACK,7:00:13 nginx超时主动断开连接,7:00:15时tomcat才返回数据,网络的问题被排除了。
那么接下来的重点就是tomcat本身,在接收问题请求的时候,tomcat服务究竟做了什么?
还是通过简单的脚本,在容易出问题的时间段连续使用jstack打印线程栈,查找出问题时处于RUNNABLE状态的catalina线程,发现这里有一句很可疑:
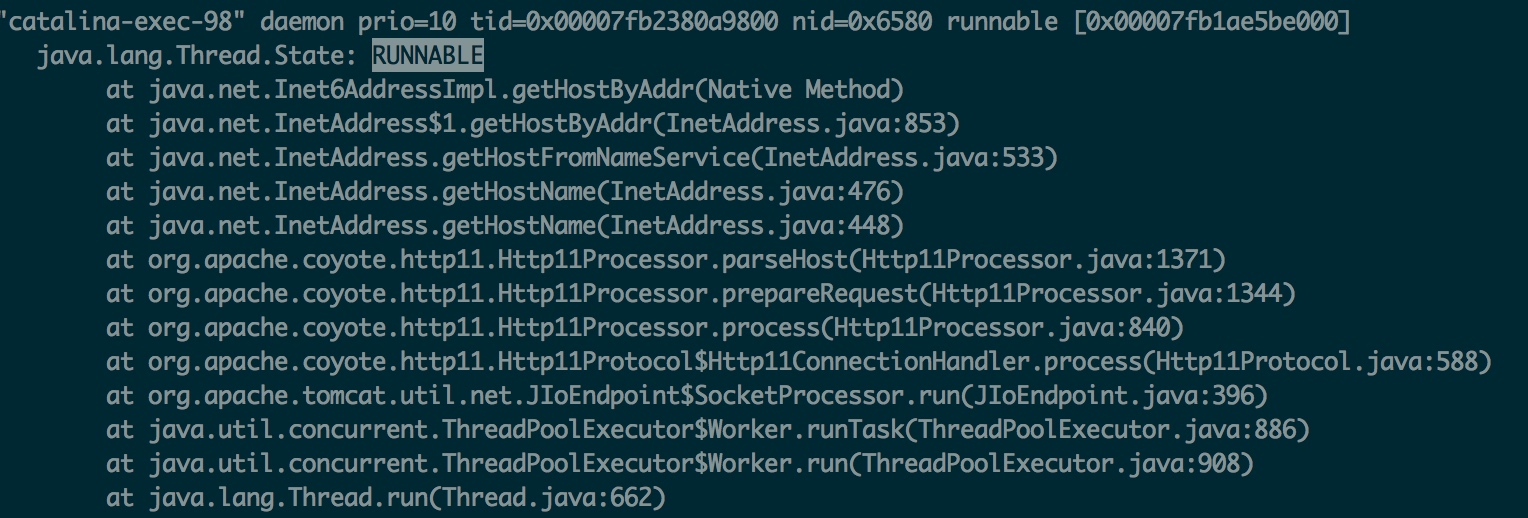
这个服务用的还是比较古老的tomcat6.0.32,查看源码,可以发现在tomcat对请求header做完解析之后会调用这个函数:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
MessageBytes valueMB = headers.getValue("host"); // Check host header if (http11 && (valueMB == null)) { error = true; // 400 - Bad request if (log.isDebugEnabled()) { log.debug(sm.getString("http11processor.request.prepare")+ " host header missing"); } response.setStatus(400); adapter.log(request, response, 0); } parseHost(valueMB); .... /** * Parse host. */ public void parseHost(MessageBytes valueMB) { if (valueMB == null || valueMB.isNull()) { // HTTP/1.0 // Default is what the socket tells us. Overriden if a host is // found/parsed request.setServerPort(socket.getLocalPort()); InetAddress localAddress = socket.getLocalAddress(); // Setting the socket-related fields. The adapter doesn't know // about socket. request.serverName().setString(localAddress.getHostName()); return; } |
也就是说,如果request请求的header里没有设置host,那么tomcat会使用自己服务器的hostname作为request对象的host属性。
再对比线上nginx探测的请求和curl发出的请求,可以看出nginx的探测请求确实没有带任何header,而curl请求默认是带了3个header的:
curl:
|
1 2 3 4 5 6 |
GET / HTTP/1.0 Host: localhost:8080 User-Agent: curl/7.43.0 Accept: */* |
nginx:
|
1 2 3 |
GET / HTTP/1.0 |
到这里可以确认,如果请求的header里没有带Host的话就有可能出现问题。找到了hang住的位置,那么接下来的问题就是,为什么这里会hang住?
第一个问题:这个getHostByAddr在做什么?翻出jvm源码,这个函数的定义在
jdk/src/share/classes/java/net/Inet4AddressImpl.java
|
1 2 |
String getHostByAddr(byte[] addr) throws UnknownHostException; |
继续研究getHostByAddr,对应的实现位于jdk/src/solaris/native/java/net/Inet6AddressImpl.c:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
/* * Class: java_net_Inet6AddressImpl * Method: getHostByAddr * Signature: (I)Ljava/lang/String; */ JNIEXPORT jstring JNICALL Java_java_net_Inet6AddressImpl_getHostByAddr(JNIEnv *env, jobject this,jbyteArray addrArray) { jstring ret = NULL; #ifdef AF_INET6 char host[NI_MAXHOST+1]; int error = 0; int len = 0; jbyte caddr[16]; if (NET_addrtransAvailable()) { struct sockaddr_in him4; struct sockaddr_in6 him6; struct sockaddr *sa; /* * For IPv4 addresses construct a sockaddr_in structure. */ if ((*env)->GetArrayLength(env, addrArray) == 4) { jint addr; (*env)->GetByteArrayRegion(env, addrArray, 0, 4, caddr); addr = ((caddr[0]<<24) & 0xff000000); addr |= ((caddr[1] <<16) & 0xff0000); addr |= ((caddr[2] <<8) & 0xff00); addr |= (caddr[3] & 0xff); memset((void *) &him4, 0, sizeof(him4)); him4.sin_addr.s_addr = (uint32_t) htonl(addr); him4.sin_family = AF_INET; sa = (struct sockaddr *) &him4; len = sizeof(him4); } else { /* * For IPv6 address construct a sockaddr_in6 structure. */ (*env)->GetByteArrayRegion(env, addrArray, 0, 16, caddr); memset((void *) &him6, 0, sizeof(him6)); memcpy((void *)&(him6.sin6_addr), caddr, sizeof(struct in6_addr) ); him6.sin6_family = AF_INET6; sa = (struct sockaddr *) &him6 ; len = sizeof(him6) ; } error = (*getnameinfo_ptr)(sa, len, host, NI_MAXHOST, NULL, 0, NI_NAMEREQD); if (!error) { ret = (*env)->NewStringUTF(env, host); } } #endif /* AF_INET6 */ if (ret == NULL) { JNU_ThrowByName(env, JNU_JAVANETPKG "UnknownHostException", NULL); } return ret; } |
getnameinfo_ptr的定义位于jdk/src/solaris/native/java/net/net_util_md.c:
|
1 2 3 |
getnameinfo_ptr = (getnameinfo_f) JVM_FindLibraryEntry(RTLD_DEFAULT, "getnameinfo"); |
实际是调用了glibc库函数,man一下getnameinfo
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
DESCRIPTION The getnameinfo() function is the inverse of getaddrinfo(3): it converts a socket address to a corresponding host and service, in a protocol-independent manner. It combines the functionality of gethostbyaddr(3) and getservbyport(3), but unlike those functions, getaddrinfo(3) is reentrant and allows programs to eliminate IPv4-versus-IPv6 dependencies. The sa argument is a pointer to a generic socket address structure (of type sockaddr_in or sockaddr_in6) of size salen that holds the input IP address and port number. The arguments host and serv are pointers to caller-allocated buffers (of size hostlen and servlen respectively) into which getnameinfo() places null-terminated strings containing the host and service names respectively. The caller can specify that no hostname (or no service name) is required by providing a NULL host (or serv) argument or a zero hostlen (or servlen) argument. However, at least one of hostname or service name must be requested. |
结合man page说明和调用的上下文可以推测出这个函数可以通过ip查host,但是是怎么查的呢?继续查找代码,首先要确定操作系统用的glibc版本:
随便在机器上编译一个c程序,使用ldd命令查看它的依赖库路径:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
[root@localhost test]# ldd a.out linux-vdso.so.1 => (0x00007fff595ff000) libc.so.6 => /lib64/libc.so.6 (0x0000003e60e00000) /lib64/ld-linux-x86-64.so.2 (0x0000003e60600000) [root@localhost test]# /lib64/libc.so.6 GNU C Library stable release version 2.12, by Roland McGrath et al. Copyright (C) 2010 Free Software Foundation, Inc. This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. Compiled by GNU CC version 4.4.7 20120313 (Red Hat 4.4.7-4). Compiled on a Linux 2.6.32 system on 2013-11-21. Available extensions: The C stubs add-on version 2.1.2. crypt add-on version 2.1 by Michael Glad and others GNU Libidn by Simon Josefsson Native POSIX Threads Library by Ulrich Drepper et al BIND-8.2.3-T5B RT using linux kernel aio libc ABIs: UNIQUE IFUNC For bug reporting instructions, please see: <http://www.gnu.org/software/libc/bugs.html>. https://www.gnu.org/software/libc/download.html |
去gnu官网下载对应版本的glibc源代码,查看源码,可以看出getnameinfo中调用了gethostbyaddr:
|
1 2 3 4 5 6 7 8 9 10 |
while (__gethostbyaddr_r ((const void *) &(((const struct sockaddr_in *)sa)->sin_addr), sizeof(struct in_addr), AF_INET, &th, tmpbuf, tmpbuflen, &h, &herrno)) if (herrno == NETDB_INTERNAL && errno == ERANGE) tmpbuf = extend_alloca (tmpbuf, tmpbuflen, 2 * tmpbuflen); else break; } |
在gethostbyaddr函数中有这么一段:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
switch (af) { case AF_INET: (void) sprintf(qbuf, "%u.%u.%u.%u.in-addr.arpa", (uaddr[3] & 0xff), (uaddr[2] & 0xff), (uaddr[1] & 0xff), (uaddr[0] & 0xff)); break; case AF_INET6: qp = qbuf; for (n = IN6ADDRSZ - 1; n >= 0; n--) { qp += SPRINTF((qp, "%x.%x.", uaddr[n] & 0xf, (uaddr[n] >> 4) & 0xf)); } strcpy(qp, "ip6.arpa"); break; default: abort(); } |
这里把ip地址按8位翻转之后,加了一个“.in-addr.arpa”后缀,之后就通过通用的函数发出dns query请求,最终会调用res_mkquery,man一下这个函数(man 3 res_mkquery):
|
1 2 |
The res_mkquery() function constructs a query message in buf of length buflen for the domain name dname. The query type op is usually QUERY, but can be any of the types defined in <arpa/nameser.h>. newrr is currently unused. |
http://linux.die.net/man/3/res_mkquery
跟dns请求相关的实现略复杂,这里不再展开。
这里可以走一个小捷径,我们写一个最简单的c程序来查看getnameinfo都大致做了什么事情:
[root@localhost test]# gcc test.c
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
#include <netdb.h> #include <stdio.h> int main() { struct sockaddr_in ip; const char *ipstr = "127.0.0.1"; int err; char host[NI_MAXHOST+1]; if (!inet_aton(ipstr, &ip)) errx(1, "can't parse IP address %s", ipstr); ip.sin_family = AF_INET; printf("noop\n"); err = getnameinfo(&ip,sizeof(ip),host,NI_MAXHOST,NULL,0 ,NI_NAMEREQD); printf("start\n"); err = getnameinfo(&ip,sizeof(ip),host,NI_MAXHOST,NULL,0 ,NI_NAMEREQD); printf("end\n"); } |
然后使用strace来跟踪系统调用:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 |
[root@localhost test]# strace ./a.out execve("./a.out", ["./a.out"], [/* 26 vars */]) = 0 brk(0) = 0x17d5000 mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7ff894dd7000 access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory) open("/etc/ld.so.cache", O_RDONLY) = 3 fstat(3, {st_mode=S_IFREG|0644, st_size=59784, ...}) = 0 mmap(NULL, 59784, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7ff894dc8000 close(3) = 0 open("/lib64/libc.so.6", O_RDONLY) = 3 read(3, "\177ELF\2\1\1\3\0\0\0\0\0\0\0\0\3\0>\0\1\0\0\0000\356\341`>\0\0\0"..., 832) = 832 fstat(3, {st_mode=S_IFREG|0755, st_size=1926800, ...}) = 0 mmap(0x3e60e00000, 3750152, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0x3e60e00000 mprotect(0x3e60f8b000, 2093056, PROT_NONE) = 0 mmap(0x3e6118a000, 20480, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x18a000) = 0x3e6118a000 mmap(0x3e6118f000, 18696, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0x3e6118f000 close(3) = 0 mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7ff894dc7000 mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7ff894dc6000 mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7ff894dc5000 arch_prctl(ARCH_SET_FS, 0x7ff894dc6700) = 0 mprotect(0x3e6118a000, 16384, PROT_READ) = 0 mprotect(0x3e6081f000, 4096, PROT_READ) = 0 munmap(0x7ff894dc8000, 59784) = 0 fstat(1, {st_mode=S_IFCHR|0620, st_rdev=makedev(136, 0), ...}) = 0 mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7ff894dd6000 write(1, "noop\n", 5noop ) = 5 socket(PF_FILE, SOCK_STREAM|SOCK_CLOEXEC|SOCK_NONBLOCK, 0) = 3 connect(3, {sa_family=AF_FILE, path="/var/run/nscd/socket"}, 110) = -1 ENOENT (No such file or directory) close(3) = 0 socket(PF_FILE, SOCK_STREAM|SOCK_CLOEXEC|SOCK_NONBLOCK, 0) = 3 connect(3, {sa_family=AF_FILE, path="/var/run/nscd/socket"}, 110) = -1 ENOENT (No such file or directory) close(3) = 0 brk(0) = 0x17d5000 brk(0x17f6000) = 0x17f6000 open("/etc/nsswitch.conf", O_RDONLY) = 3 fstat(3, {st_mode=S_IFREG|0644, st_size=1688, ...}) = 0 mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7ff894dd5000 read(3, "#\n# /etc/nsswitch.conf\n#\n# An ex"..., 4096) = 1688 read(3, "", 4096) = 0 close(3) = 0 munmap(0x7ff894dd5000, 4096) = 0 open("/etc/ld.so.cache", O_RDONLY) = 3 fstat(3, {st_mode=S_IFREG|0644, st_size=59784, ...}) = 0 mmap(NULL, 59784, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7ff894db6000 close(3) = 0 open("/lib64/libnss_files.so.2", O_RDONLY) = 3 read(3, "\177ELF\2\1\1\0\0\0\0\0\0\0\0\0\3\0>\0\1\0\0\0\360!\0\0\0\0\0\0"..., 832) = 832 fstat(3, {st_mode=S_IFREG|0755, st_size=65928, ...}) = 0 mmap(NULL, 2151824, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0x7ff894ba8000 mprotect(0x7ff894bb4000, 2097152, PROT_NONE) = 0 mmap(0x7ff894db4000, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0xc000) = 0x7ff894db4000 close(3) = 0 mprotect(0x7ff894db4000, 4096, PROT_READ) = 0 munmap(0x7ff894db6000, 59784) = 0 getpid() = 28054 open("/etc/resolv.conf", O_RDONLY) = 3 fstat(3, {st_mode=S_IFREG|0644, st_size=50, ...}) = 0 mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7ff894dd5000 read(3, "nameserver 172.16.xx.xx\nnamese"..., 4096) = 50 read(3, "", 4096) = 0 close(3) = 0 munmap(0x7ff894dd5000, 4096) = 0 uname({sys="Linux", node="localhost.localdomain", ...}) = 0 open("/etc/host.conf", O_RDONLY) = 3 fstat(3, {st_mode=S_IFREG|0644, st_size=9, ...}) = 0 mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7ff894dd5000 read(3, "multi on\n", 4096) = 9 read(3, "", 4096) = 0 close(3) = 0 munmap(0x7ff894dd5000, 4096) = 0 open("/etc/hosts", O_RDONLY|O_CLOEXEC) = 3 fcntl(3, F_GETFD) = 0x1 (flags FD_CLOEXEC) fstat(3, {st_mode=S_IFREG|0644, st_size=400, ...}) = 0 mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7ff894dd5000 read(3, "127.0.0.1 localhost localhost."..., 4096) = 400 read(3, "", 4096) = 0 close(3) = 0 munmap(0x7ff894dd5000, 4096) = 0 open("/etc/ld.so.cache", O_RDONLY) = 3 fstat(3, {st_mode=S_IFREG|0644, st_size=59784, ...}) = 0 mmap(NULL, 59784, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7ff894db6000 close(3) = 0 open("/lib64/libnss_dns.so.2", O_RDONLY) = 3 read(3, "\177ELF\2\1\1\0\0\0\0\0\0\0\0\0\3\0>\0\1\0\0\0\0\20\0\0\0\0\0\0"..., 832) = 832 fstat(3, {st_mode=S_IFREG|0755, st_size=27424, ...}) = 0 mmap(NULL, 2117880, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0x7ff8949a2000 mprotect(0x7ff8949a7000, 2093056, PROT_NONE) = 0 mmap(0x7ff894ba6000, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x4000) = 0x7ff894ba6000 close(3) = 0 open("/lib64/libresolv.so.2", O_RDONLY) = 3 read(3, "\177ELF\2\1\1\0\0\0\0\0\0\0\0\0\3\0>\0\1\0\0\00009\240b>\0\0\0"..., 832) = 832 fstat(3, {st_mode=S_IFREG|0755, st_size=113952, ...}) = 0 mmap(0x3e62a00000, 2202248, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0x3e62a00000 mprotect(0x3e62a16000, 2097152, PROT_NONE) = 0 mmap(0x3e62c16000, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x16000) = 0x3e62c16000 mmap(0x3e62c18000, 6792, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0x3e62c18000 close(3) = 0 mprotect(0x3e62c16000, 4096, PROT_READ) = 0 mprotect(0x7ff894ba6000, 4096, PROT_READ) = 0 munmap(0x7ff894db6000, 59784) = 0 socket(PF_INET, SOCK_DGRAM|SOCK_NONBLOCK, IPPROTO_IP) = 3 connect(3, {sa_family=AF_INET, sin_port=htons(53), sin_addr=inet_addr("172.16.xx.xx")}, 16) = 0 poll([{fd=3, events=POLLOUT}], 1, 0) = 1 ([{fd=3, revents=POLLOUT}]) sendto(3, "\36\247\1\0\0\1\0\0\0\0\0\0\0010\0010\0010\0010\7in-addr\4arp"..., 38, MSG_NOSIGNAL, NULL, 0) = 38 poll([{fd=3, events=POLLIN}], 1, 5000) = 1 ([{fd=3, revents=POLLIN}]) ioctl(3, FIONREAD, [73]) = 0 recvfrom(3, "\36\247\205\203\0\1\0\0\0\1\0\0\0010\0010\0010\0010\7in-addr\4arp"..., 1024, 0, {sa_family=AF_INET, sin_port=htons(53), sin_addr=inet_addr("172.16.xx.xx")}, [16]) = 73 close(3) = 0 write(1, "start\n", 6start ) = 6 open("/etc/hosts", O_RDONLY|O_CLOEXEC) = 3 fstat(3, {st_mode=S_IFREG|0644, st_size=400, ...}) = 0 mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7ff894dd5000 read(3, "127.0.0.1 localhost localhost."..., 4096) = 400 read(3, "", 4096) = 0 close(3) = 0 munmap(0x7ff894dd5000, 4096) = 0 socket(PF_INET, SOCK_DGRAM|SOCK_NONBLOCK, IPPROTO_IP) = 3 connect(3, {sa_family=AF_INET, sin_port=htons(53), sin_addr=inet_addr("172.16.xx.xx")}, 16) = 0 poll([{fd=3, events=POLLOUT}], 1, 0) = 1 ([{fd=3, revents=POLLOUT}]) sendto(3, "~\223\1\0\0\1\0\0\0\0\0\0\0010\0010\0010\0010\7in-addr\4arp"..., 38, MSG_NOSIGNAL, NULL, 0) = 38 poll([{fd=3, events=POLLIN}], 1, 5000) = 1 ([{fd=3, revents=POLLIN}]) ioctl(3, FIONREAD, [73]) = 0 recvfrom(3, "~\223\205\203\0\1\0\0\0\1\0\0\0010\0010\0010\0010\7in-addr\4arp"..., 1024, 0, {sa_family=AF_INET, sin_port=htons(53), sin_addr=inet_addr("172.16.xx.xx")}, [16]) = 73 close(3) = 0 write(1, "end\n", 4end ) = 4 exit_group(4) = ? |
可以看出,首次查询时会读取/etc/nsswitch.conf,/etc/resolv.conf,后面的请求先读了/etc/hosts,找不到就向dns服务器发送了一个udp查询请求(SOCK_DGRAM),之后使用了poll等待返回结果,有返回的话使用recvfrom接收结果。
为了验证看代码得到的结果再次抓包,不过这次只过滤53端口的数据包(dns服务的端口为53):
|
1 2 3 4 5 6 7 8 9 |
[root@79-40-151-yf-core logs]# tcpdump -i eth1 port 53 tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on eth1, link-type EN10MB (Ethernet), capture size 65535 bytes 18:26:42.135322 IP 10.79.40.xx.35611 > 10.71.16.xx.domain: 59106+ PTR? xx.40.79.10.in-addr.arpa. (43) 18:26:42.135348 IP 10.79.40.xx.35611 > 172.16.xx.xx.domain: 59106+ PTR? xx.40.79.10.in-addr.arpa. (43) 18:26:42.136024 IP 172.16.xx.xx.domain > 10.79.40.xx.35611: 59106 NXDomain 0/0/0 (43) 18:26:42.136258 IP 10.79.40.xx.43068 > 10.71.16.xx.domain: 32990+ PTR? xx.16.71.10.in-addr.arpa. (43) 18:26:42.136276 IP 10.79.40.xx.43068 > 172.16.xx.xx.domain: 32990+ PTR? xx.16.71.10.in-addr.arpa. (43) |
跟前面推测的一样,这里确实在向dns服务器发送这种后缀是.in-addr.arpa的请求。
可用在wiki上找到这类查询的详细描述:https://en.wikipedia.org/wiki/Reverse_DNS_lookup
最后一个问题是这个查询会超时吗?超时时间是多少?根据man page结果,dns查询的超时是5秒:
|
1 2 3 4 5 6 7 |
$ man resolv.conf ... timeout:n sets the amount of time the resolver will wait for a response from a remote name server before retrying the query via a different name server. Measured in seconds, the default is RES_TIMEOUT (currently 5, see <resolv.h>). The value for this option is silently capped to 30. ... |
跟抓包结果一致,并且注意到strace中poll的最后一个参数是5000,和默认的超时时间一致。
我们可以在/etc/resolv.conf里增加关于超时时间的配置:
|
1 2 |
options timeout:1 |
再用strace试一下,果然poll的参数变成1000了。
但是线上机器配置了dnsmasq缓存,为什么缓存没有生效?
配置了dnsmasq后再次使用tcpdump,可用看到lo网卡和eth1网卡都有查询请求,由于反向dns查询不到主机名,dnsmasq无法缓存结果,只能每次都把请求转发给实际dns。
线上除了这个网段的机器还有其他机器,为什么其他机器没有问题?
没出问题的机器里/etc/hosts配置了本机ip对应的hostname,在hosts文件中查询到了就不会再去搜索dns。
DNS解析在那个时间为什么会消耗5秒?
由于udp协议本身传输不可靠没有重发的机制,在网络异常的时候只能默默的等待超时,具体网络的问题这里就不展开了。
如何解决这个问题?
- 首先第一反应是想到升级tomcat版本,查看新版tomcat代码,有问题的代码果然没有了,线上服务升级到tomcat8后也恢复了正常。
- 如果不能升级tomcat,可以在nginx的探测增加host header,避免前端机反向查询请求。
- 如果两者都不能做,那么可以在本机hosts中配置对应本机ip的hostname,可以避免通过dns服务器查询。

本作品采用知识共享署名-非商业性使用 4.0 国际许可协议进行许可,转载请注明作者及原网址。
我猜,特定时间出现问题,应该是由于那个时段的访问量大造成的吧。其它时段没有那么大,应该是能够撑住访问量。
不知道大家有没有这个习惯,当我们小便的时候发现便池里有一只虫子,就会对着虫子尿,直到把虫子淹死才甘心。
神回复:刚尿完虫就飞脸上了。 http://www.1024xyz.com
同问
为什么只有特定时间会出这个问题呢?